[CVPR24 Vision Foundation Models Tutorial] Video and 3D Generation by Kevin Lin
bilibili: https://www.bilibili.com/video/BV12T421e7TG
In this talk, I will provide a brief review of recent advancements in video and 3D generation. Diffusion models have made significant advancements in recent years, especially for video generation. The results, as seen in the slides, are quite impressive. Progress has been made from low to high resolution video, extending from very short, four-second clips to one-minute-long videos, while preserving the correct identity and maintaining 3D consistency. An important takeaway from the SORA research is that researchers have found that developing a video generation model is a very promising path toward building a general-purpose simulator.
 For the physical world, here is the outline for today's presentation. We will start by introducing the development of video diffusion models, followed by several key observations in the latest video generation research. Next, we will discuss some rapidly growing topics this year. Firstly, an important and exciting topic is developing a training-efficient approach for building video diffusion models. Secondly, we will also explore accelerating video diffusion inference, focusing mainly on few-step diffusion distillation for the video diffusion model. Lastly, we will cover topics related to generating diverse video content, such as long video generation, video editing, and 3D generation. A representative task in video generation is creating video from text, commonly referred to as text-to-video or T2V. Given an input text prompt as shown in the slide, the goal of video generation is to produce a video that accurately represents the provided text description. This is related to the previous discussion on text-to-image generation. One significant challenge, or the main difference, is addressing coherent and consistent visual element generation across the temporal dimension.
For the physical world, here is the outline for today's presentation. We will start by introducing the development of video diffusion models, followed by several key observations in the latest video generation research. Next, we will discuss some rapidly growing topics this year. Firstly, an important and exciting topic is developing a training-efficient approach for building video diffusion models. Secondly, we will also explore accelerating video diffusion inference, focusing mainly on few-step diffusion distillation for the video diffusion model. Lastly, we will cover topics related to generating diverse video content, such as long video generation, video editing, and 3D generation. A representative task in video generation is creating video from text, commonly referred to as text-to-video or T2V. Given an input text prompt as shown in the slide, the goal of video generation is to produce a video that accurately represents the provided text description. This is related to the previous discussion on text-to-image generation. One significant challenge, or the main difference, is addressing coherent and consistent visual element generation across the temporal dimension.
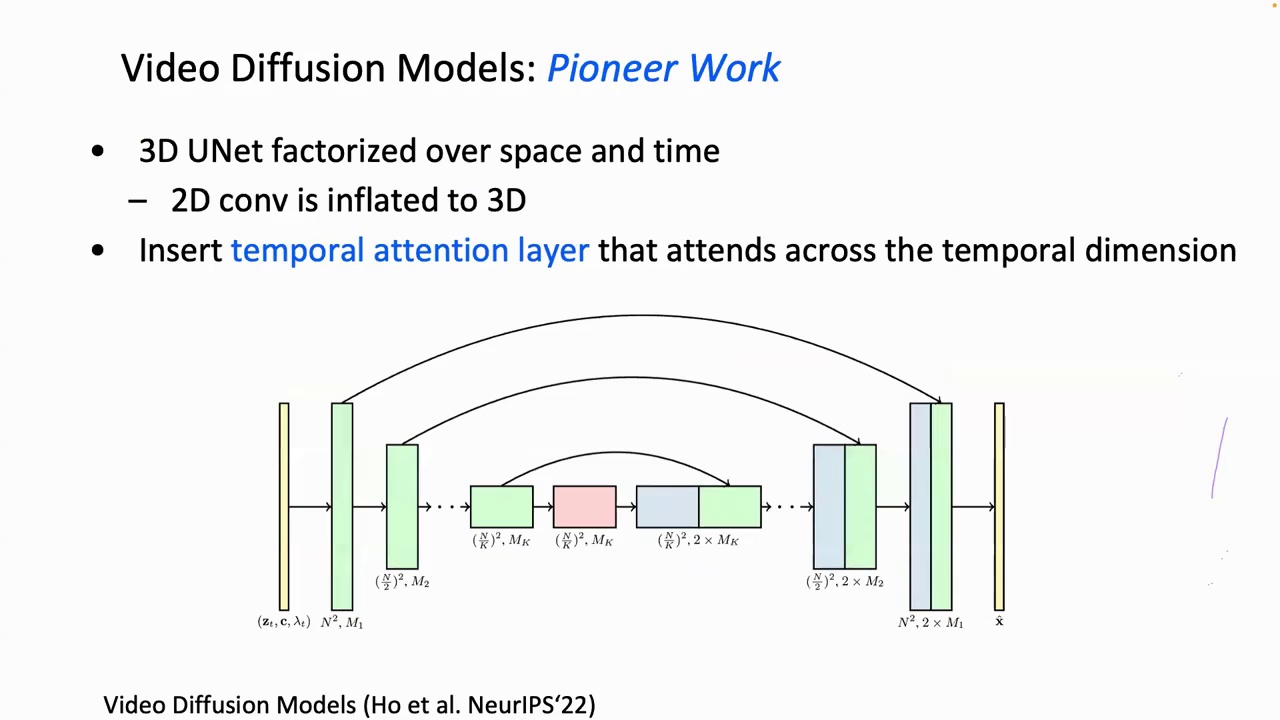 To address the challenge, particularly in the temporal dimension, researchers have discovered that inflating the UNet in the image diffusion model to 3D is a promising approach. This method provides several advantages. Firstly, it allows the use of a well-pre-trained text-to-image generation model for initialization and further training. Secondly, by incorporating additional temporal attention layers, the model can train both the UNet and the newly introduced parameters, enabling it to effectively model object motions.
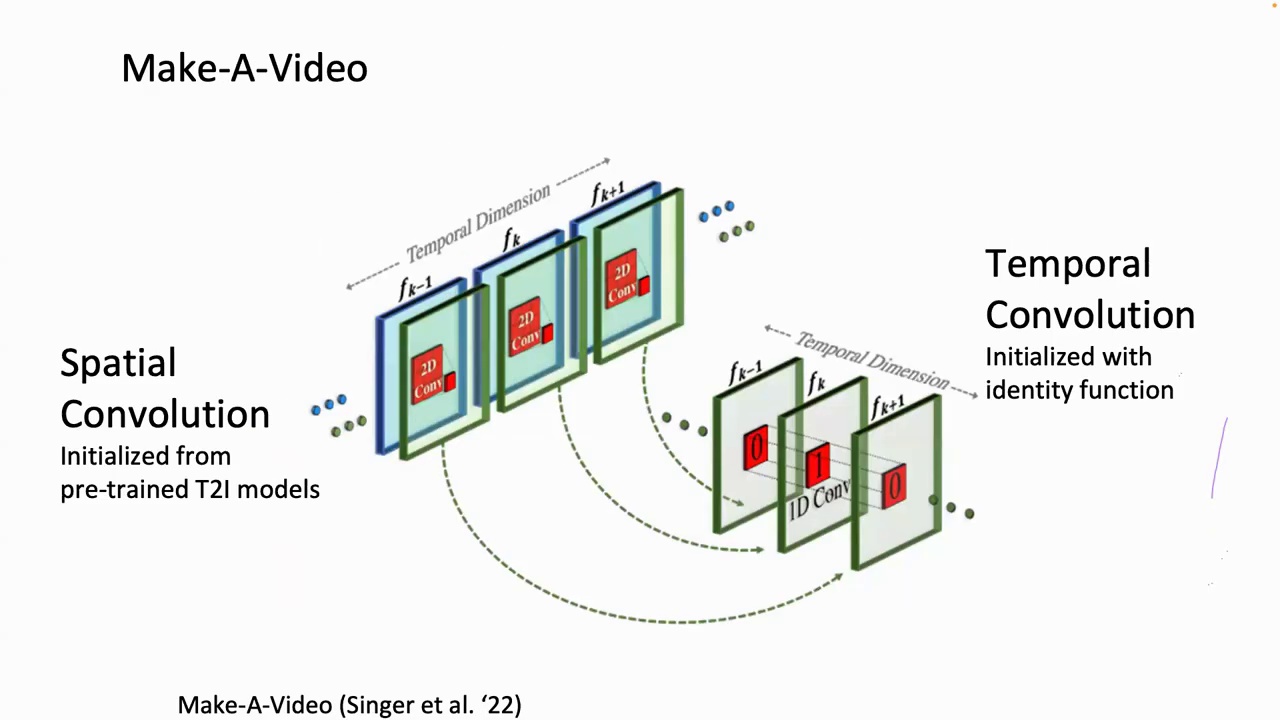
So, here, this is an example that demonstrates how researchers enable the transition from the pre-trained text-to-image model to the temporal dimension. We can see that each spatial 2D convolution layer is followed by a temporal 1D convolution layer, and the temporal convolution layer is initialized as an identity function. Given this modification, we further train the model using text-video-pairs data to learn video generation. This is about extending the convolution.
To the temporal dimension, we also apply temporal attention layers. These layers follow the spatial attention layers. The temporal attention layers are initialized with a temporal zero projection, resulting in an identity function.
So with the inflated UNet, our researchers discovered that we can fine-tune the inflated UNet on small, high-quality video datasets and demonstrate in pioneering research. This fine-tuned model is capable of generating shorter video clips with specific video content. One important question is, how can we train a video diffusion model for a wider range of visual content? Along this research line, as shown by Stability AI researchers, they found that if we
To address the challenge, particularly in the temporal dimension, researchers have discovered that inflating the UNet in the image diffusion model to 3D is a promising approach. This method provides several advantages. Firstly, it allows the use of a well-pre-trained text-to-image generation model for initialization and further training. Secondly, by incorporating additional temporal attention layers, the model can train both the UNet and the newly introduced parameters, enabling it to effectively model object motions.
So, here, this is an example that demonstrates how researchers enable the transition from the pre-trained text-to-image model to the temporal dimension. We can see that each spatial 2D convolution layer is followed by a temporal 1D convolution layer, and the temporal convolution layer is initialized as an identity function. Given this modification, we further train the model using text-video-pairs data to learn video generation. This is about extending the convolution.
To the temporal dimension, we also apply temporal attention layers. These layers follow the spatial attention layers. The temporal attention layers are initialized with a temporal zero projection, resulting in an identity function.
So with the inflated UNet, our researchers discovered that we can fine-tune the inflated UNet on small, high-quality video datasets and demonstrate in pioneering research. This fine-tuned model is capable of generating shorter video clips with specific video content. One important question is, how can we train a video diffusion model for a wider range of visual content? Along this research line, as shown by Stability AI researchers, they found that if we
 Continuing to scale up the training data, as AI researchers have done, involves building a system that curates large amounts of video data and transforms the large, noisy video data into a suitable dataset for generated video models. This demonstrates that by simply scaling up the training data, we can directly achieve significant quality improvements. In addition to the training data, another crucial factor is the model size, which also plays a vital role in performance enhancement. As shown in the SORA technical reports, the diffusion model can be effectively scaled. In this comparison, with a fixed state and input prompt, as training continues, we observe that sample quality improves with increased training computations.
So now we have discussed the large video foundation model, and we will next discuss some important findings and highlights in two important directions to improve video generation.
Model efficiency is a key direction, focusing on developing techniques that enhance training efficiency. Ideally, we aim to achieve high performance with a minimal amount of training data and potentially a shorter training duration. Nonetheless, this remains a challenging and unresolved issue.
Recently, some interesting research, such as AnimateDiff, has proposed inserting motion modules into a pre-trained personalized tactile image model. By training only the motion modules, the model can learn motion priors while mitigating visual quality degradation. This provides a practical pipeline for directly converting a personalized tactile image model into an animation generation tool.
So we briefly discussed training efficiency techniques. Another practical topic is accelerating the diffusion sampling process, particularly by reducing the number of sampling steps while maintaining similar visual quality. As we can see on the left-hand side, this is the result from the eMove video paper. Typically, they usually require about 200 sampling steps in the inference stage. It would be beneficial if we could reduce the sampling steps to four, two, or even just one step.
As discussed in previous sessions, the consistency model is a promising method for faster image generation. It introduces a new learning objective that maps noisy images at any time step to their initial states in the diffusion process. However, applying this directly to video generation may be challenging due to the need to consider both spatial and temporal dimensions, which includes accounting for motion and appearance.
Consistency is a significant issue. Despite the abundance of high-quality, high-resolution image data, video data frequently suffers from low quality and often includes watermarks. This presents a data challenge that complicates the distillation process.
Recently, a paper titled "Motion Consistency Model" has been published. The authors suggest distilling the motion prior from text-to-video teachers and propose enhancing frame quality using additional high-quality image datasets. This Motion Consistency Model not only significantly reduces the number of sampling steps but also leverages various image data to improve video frame quality. In the slides...
It demonstrates some of the quality results using various image datasets, such as using WebVid video frames exclusively, or employing live video footage.
Or 3D cartoon style image datasets. Then the MCM can generate diverse and good results.
Next, we will discuss how we apply the video diffusion model for diverse content creation. We will highlight three fundamental challenges in this area. The first challenge is generating long videos or variable durations. The second fundamental challenge is ensuring controllability in the video diffusion model. Finally, maintaining consistency during video generation is always an important challenge. Specifically, for generating variable video durations, one challenge is to produce long videos.
To generate a variable video length to enable an extremely long video is quite challenging, and recent studies have highlighted several issues.
Problems in progress, like using a coarse-to-fine process to find probes, such as
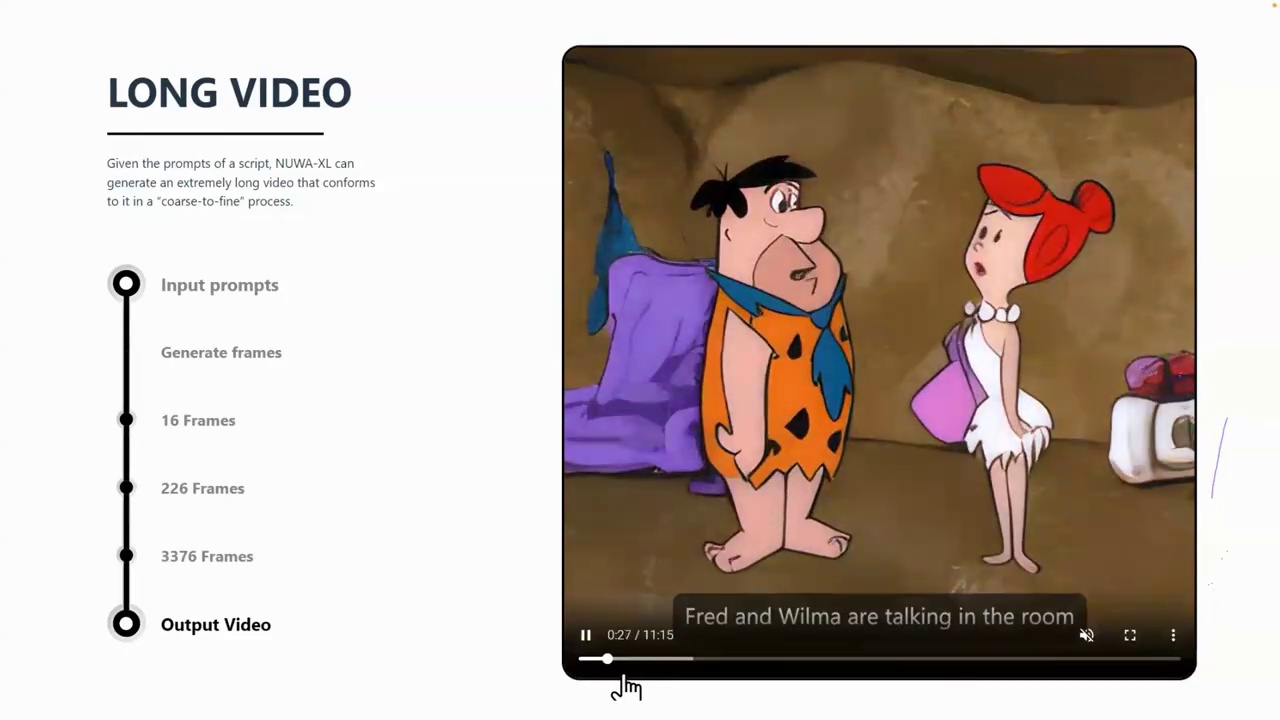
As demonstrated in the example, the author suggests initially generating a small number of frames, such as 16 frames. Subsequently, based on these 16 frames, the process continues to produce approximately 200 frames, followed by 3,000 frames. Ultimately, this leads to the creation of a lengthy video.
In this video, the author proposes a coarse-to-fine approach, which can be described as diffusion over diffusion. Initially, a global diffusion model is used to generate keyframes, forming a coarse storyline of the video. Subsequently, a series of local diffusion models are applied to adjacent frames, treating them as the first and last frames, to iteratively complete the middle frames, resulting in a total of fine frames.
In the previous example, researchers primarily focused on relatively simple scenarios, such as cartoon videos. Another important and highly challenging direction is the creation of rich and diverse video content. Can we generate video content similar to TikTok?
Videos. Recently, researchers have explored the direction of generating human dance videos. This task is more challenging than creating cartoons, as it requires accurate body pose and realistic appearance. Promising progress has been made in this area, with the ability to compose different subjects in the same dance pose.
Similarly, we can also compose different poses with the same subject.
Continuing to scale up the training data, as AI researchers have done, involves building a system that curates large amounts of video data and transforms the large, noisy video data into a suitable dataset for generated video models. This demonstrates that by simply scaling up the training data, we can directly achieve significant quality improvements. In addition to the training data, another crucial factor is the model size, which also plays a vital role in performance enhancement. As shown in the SORA technical reports, the diffusion model can be effectively scaled. In this comparison, with a fixed state and input prompt, as training continues, we observe that sample quality improves with increased training computations.
So now we have discussed the large video foundation model, and we will next discuss some important findings and highlights in two important directions to improve video generation.
Model efficiency is a key direction, focusing on developing techniques that enhance training efficiency. Ideally, we aim to achieve high performance with a minimal amount of training data and potentially a shorter training duration. Nonetheless, this remains a challenging and unresolved issue.
Recently, some interesting research, such as AnimateDiff, has proposed inserting motion modules into a pre-trained personalized tactile image model. By training only the motion modules, the model can learn motion priors while mitigating visual quality degradation. This provides a practical pipeline for directly converting a personalized tactile image model into an animation generation tool.
So we briefly discussed training efficiency techniques. Another practical topic is accelerating the diffusion sampling process, particularly by reducing the number of sampling steps while maintaining similar visual quality. As we can see on the left-hand side, this is the result from the eMove video paper. Typically, they usually require about 200 sampling steps in the inference stage. It would be beneficial if we could reduce the sampling steps to four, two, or even just one step.
As discussed in previous sessions, the consistency model is a promising method for faster image generation. It introduces a new learning objective that maps noisy images at any time step to their initial states in the diffusion process. However, applying this directly to video generation may be challenging due to the need to consider both spatial and temporal dimensions, which includes accounting for motion and appearance.
Consistency is a significant issue. Despite the abundance of high-quality, high-resolution image data, video data frequently suffers from low quality and often includes watermarks. This presents a data challenge that complicates the distillation process.
Recently, a paper titled "Motion Consistency Model" has been published. The authors suggest distilling the motion prior from text-to-video teachers and propose enhancing frame quality using additional high-quality image datasets. This Motion Consistency Model not only significantly reduces the number of sampling steps but also leverages various image data to improve video frame quality. In the slides...
It demonstrates some of the quality results using various image datasets, such as using WebVid video frames exclusively, or employing live video footage.
Or 3D cartoon style image datasets. Then the MCM can generate diverse and good results.
Next, we will discuss how we apply the video diffusion model for diverse content creation. We will highlight three fundamental challenges in this area. The first challenge is generating long videos or variable durations. The second fundamental challenge is ensuring controllability in the video diffusion model. Finally, maintaining consistency during video generation is always an important challenge. Specifically, for generating variable video durations, one challenge is to produce long videos.
To generate a variable video length to enable an extremely long video is quite challenging, and recent studies have highlighted several issues.
Problems in progress, like using a coarse-to-fine process to find probes, such as
As demonstrated in the example, the author suggests initially generating a small number of frames, such as 16 frames. Subsequently, based on these 16 frames, the process continues to produce approximately 200 frames, followed by 3,000 frames. Ultimately, this leads to the creation of a lengthy video.
In this video, the author proposes a coarse-to-fine approach, which can be described as diffusion over diffusion. Initially, a global diffusion model is used to generate keyframes, forming a coarse storyline of the video. Subsequently, a series of local diffusion models are applied to adjacent frames, treating them as the first and last frames, to iteratively complete the middle frames, resulting in a total of fine frames.
In the previous example, researchers primarily focused on relatively simple scenarios, such as cartoon videos. Another important and highly challenging direction is the creation of rich and diverse video content. Can we generate video content similar to TikTok?
Videos. Recently, researchers have explored the direction of generating human dance videos. This task is more challenging than creating cartoons, as it requires accurate body pose and realistic appearance. Promising progress has been made in this area, with the ability to compose different subjects in the same dance pose.
Similarly, we can also compose different poses with the same subject.
 So, the core idea in this work is that we can leverage the ControlNet and UNet together to combine them for video human dance generation. The author proposes to disentangle the control from three conditions: input frame, background, and pose. This method enables arbitrary compositionality for human subjects, backgrounds, and dance moves. In addition to human dancing videos, recent research also shows that we can synthesize a series of diverse 3D scenes starting from arbitrary locations or specified by a single image or a language description. In this work, the author proposes to use a large language model to generate scene descriptions, then employ text-driven visual scene generation, and finally use text-to-text guided all painting to generate the complete scene. This demonstrates a promising signal that we can generate a long sequence of diverse and connected 3D scenes by leveraging existing all painting and scene generation approaches. Recent studies have shown great advancements using multi-view diffusion models. For example, CAT 3D uses a multi-view latent diffusion model to generate novel views of the scene. This model can be conditioned on any number of views and is trained to produce multiple views.
So, the core idea in this work is that we can leverage the ControlNet and UNet together to combine them for video human dance generation. The author proposes to disentangle the control from three conditions: input frame, background, and pose. This method enables arbitrary compositionality for human subjects, backgrounds, and dance moves. In addition to human dancing videos, recent research also shows that we can synthesize a series of diverse 3D scenes starting from arbitrary locations or specified by a single image or a language description. In this work, the author proposes to use a large language model to generate scene descriptions, then employ text-driven visual scene generation, and finally use text-to-text guided all painting to generate the complete scene. This demonstrates a promising signal that we can generate a long sequence of diverse and connected 3D scenes by leveraging existing all painting and scene generation approaches. Recent studies have shown great advancements using multi-view diffusion models. For example, CAT 3D uses a multi-view latent diffusion model to generate novel views of the scene. This model can be conditioned on any number of views and is trained to produce multiple views.
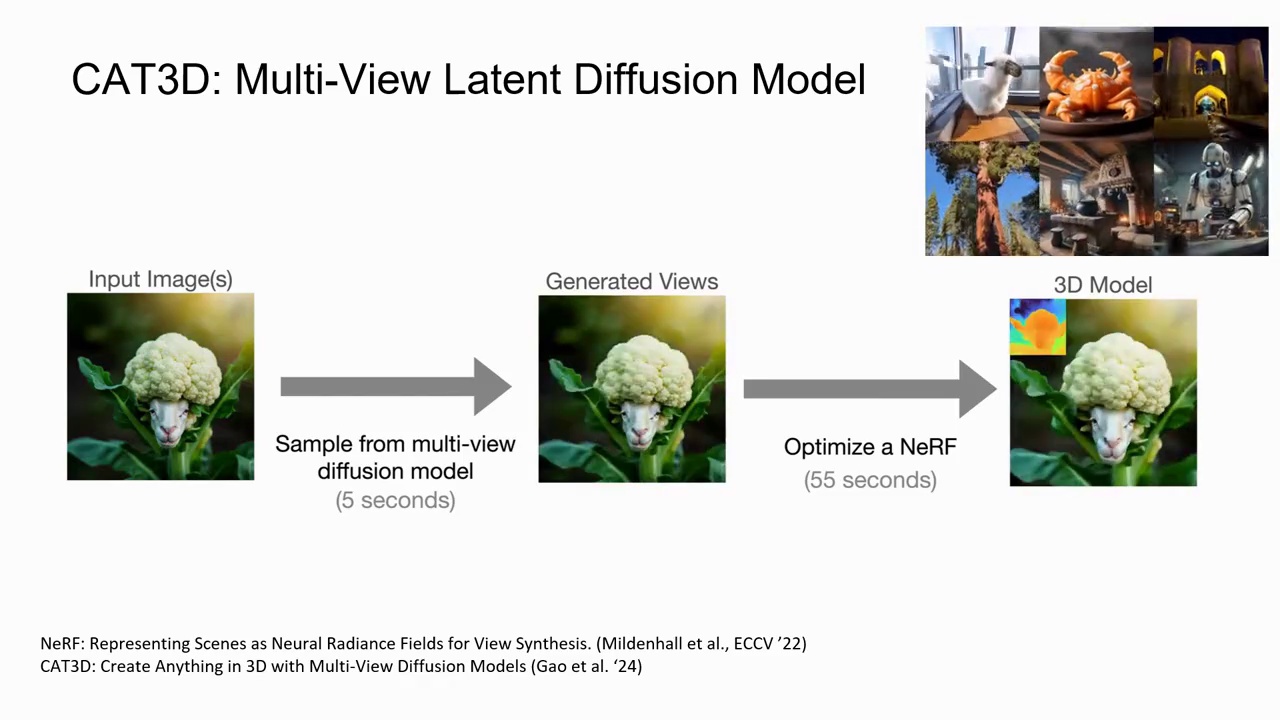 Consistent novel images of the scene at a specific target viewpoint are generated. In the proposed method, the model architecture is similar to video diffusion models, but with camera pose and balance for each image instead of time and balance. The generated views are passed into a robust 3D reconstruction pipeline to generate the 3D representation.
Consistent novel images of the scene at a specific target viewpoint are generated. In the proposed method, the model architecture is similar to video diffusion models, but with camera pose and balance for each image instead of time and balance. The generated views are passed into a robust 3D reconstruction pipeline to generate the 3D representation.
 So far, we have discussed topics such as coherent video generation, as demonstrated in the long video example. We have also explored realistic content generation, including the use of human pose as a condition for generating human dance videos. Additionally, we have highlighted recent advancements in 3D consistency, which are crucial milestones in developing a world simulator. As shown in the video results, Sora can generate videos with dynamic camera motion. As the camera rotates, we observe that people and scene elements move consistently in 3D space. Sora also generates long videos while maintaining character identity, even in cases of occlusion or when the subject leaves the frame. Although Sora has shown promising results, there are still many opportunities and challenges ahead.
So far, we have discussed topics such as coherent video generation, as demonstrated in the long video example. We have also explored realistic content generation, including the use of human pose as a condition for generating human dance videos. Additionally, we have highlighted recent advancements in 3D consistency, which are crucial milestones in developing a world simulator. As shown in the video results, Sora can generate videos with dynamic camera motion. As the camera rotates, we observe that people and scene elements move consistently in 3D space. Sora also generates long videos while maintaining character identity, even in cases of occlusion or when the subject leaves the frame. Although Sora has shown promising results, there are still many opportunities and challenges ahead.
 Challenges. The first challenge is accurately modeling the physical and digital world when building the world simulator. State-of-the-art models still have room for improvement. They may struggle to simulate the physics of complex scenes and may not fully comprehend the specific instance of cause and effect as the models are primarily trained on video text data. We may need new training approaches to learn abstract concepts that are difficult to describe in language. The second challenge is evaluation. We need new evaluation benchmarks and metrics to assess the quality of the video generation models. Finally, safety and privacy are crucial topics. It would be helpful to build tools to detect misleading video content. We should engage artists and general users in the world to understand their concerns and identify their positive and negative use cases for this new technology.
Challenges. The first challenge is accurately modeling the physical and digital world when building the world simulator. State-of-the-art models still have room for improvement. They may struggle to simulate the physics of complex scenes and may not fully comprehend the specific instance of cause and effect as the models are primarily trained on video text data. We may need new training approaches to learn abstract concepts that are difficult to describe in language. The second challenge is evaluation. We need new evaluation benchmarks and metrics to assess the quality of the video generation models. Finally, safety and privacy are crucial topics. It would be helpful to build tools to detect misleading video content. We should engage artists and general users in the world to understand their concerns and identify their positive and negative use cases for this new technology.
 We recently introduced a new evaluation benchmark called MMWorld. This benchmark aims to evaluate multiple capabilities of the world model in videos, such as future prediction, attribute or temporal understanding, and counterfactual thinking ability.
So, what exactly is a world model? According to researchers, a world model refers to our ability to construct internal representations of the world, predict and simulate future events within these representations. By predicting the future, we can reason and plan more effectively. Given these concepts, it presents a significant opportunity for us to reconsider the design and development of video diffusion models.
We recently introduced a new evaluation benchmark called MMWorld. This benchmark aims to evaluate multiple capabilities of the world model in videos, such as future prediction, attribute or temporal understanding, and counterfactual thinking ability.
So, what exactly is a world model? According to researchers, a world model refers to our ability to construct internal representations of the world, predict and simulate future events within these representations. By predicting the future, we can reason and plan more effectively. Given these concepts, it presents a significant opportunity for us to reconsider the design and development of video diffusion models.
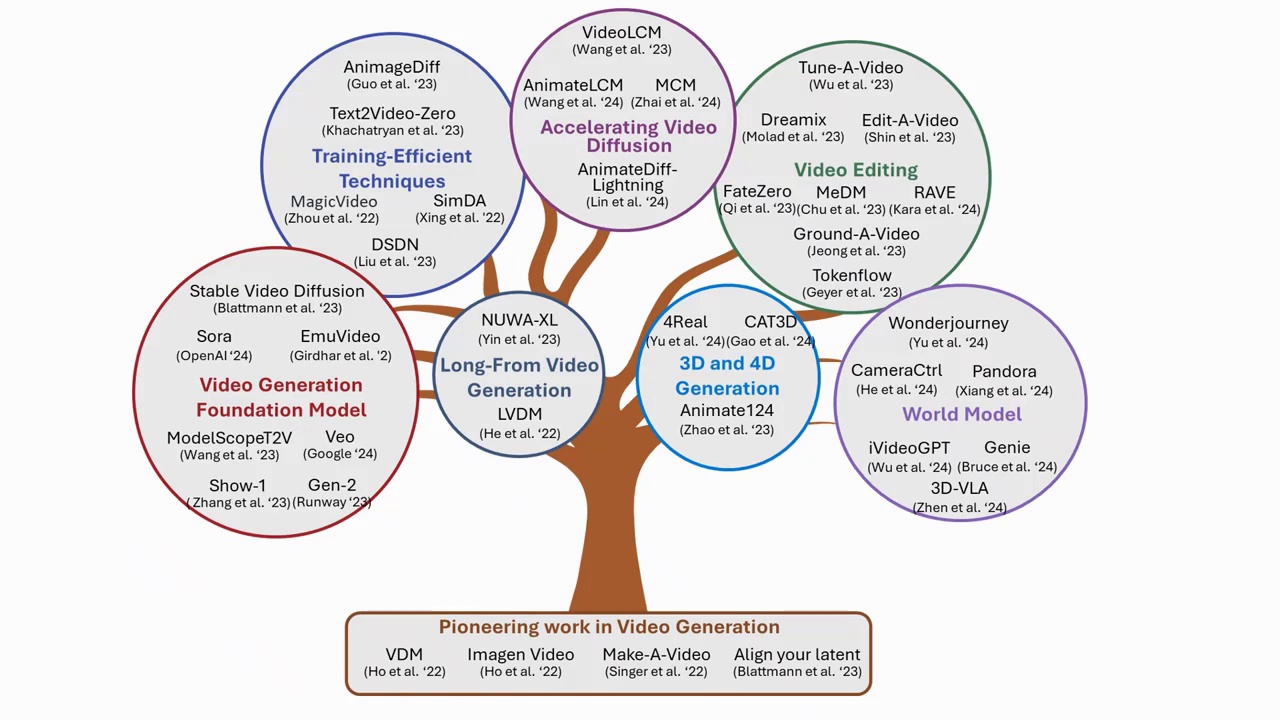 I would like to summarize today's talk. First, we discussed innovative work in video diffusion, such as incorporating temporal attention into existing UNet architectures for motion modeling. We further highlighted the key findings in the latest video generation foundation models. For instance, we highlighted how scaling data and model size significantly improve performance. We covered techniques to reduce training costs, such as training motion modules, as demonstrated in AnimateDiff. We discussed challenges and research efforts aimed at speeding up video generation. We briefly touched on topics like long video generation, conditional video generation, and 3D generation.
Finally, I would like to thank our outstanding interns for supporting this tutorial. Here is a list of online resources, including YouTube and blog tutorials on diffusion models. You may find this helpful. Thank you.
I would like to summarize today's talk. First, we discussed innovative work in video diffusion, such as incorporating temporal attention into existing UNet architectures for motion modeling. We further highlighted the key findings in the latest video generation foundation models. For instance, we highlighted how scaling data and model size significantly improve performance. We covered techniques to reduce training costs, such as training motion modules, as demonstrated in AnimateDiff. We discussed challenges and research efforts aimed at speeding up video generation. We briefly touched on topics like long video generation, conditional video generation, and 3D generation.
Finally, I would like to thank our outstanding interns for supporting this tutorial. Here is a list of online resources, including YouTube and blog tutorials on diffusion models. You may find this helpful. Thank you.